En la entrada anterior de esta serie de posts dedicados a la auditoría de código, hicimos una introducción sobre los problemas derivados del trabajo habitual. Es muy normal que haya fallos, descuidos o simple desconocimiento en cualquier proceso en el que un humano participa.
Vimos que el desarrollo de software no es una excepción y pudimos comprobar cómo han ido evolucionando los proyectos para convertirse en auténticos mastodontes.
Llegamos a la conclusión de que auditar el código de grandes proyectos es algo necesario y establecimos un momento óptimo cercano al 70% de desarrollo sobre una rama estable y que pueda compilar. ¿Hasta aquí todo bien? ¿Seguimos?
Primer acercamiento al código fuente
Si el código no es nuestro (lo que es común en una auditoría) necesitamos saber a qué nos enfrentamos. No tardaremos lo mismo ni nos encontraremos con los mismos problemas en un proyecto con miles de líneas pero sencillo, que en otro con pocas pero excesivamente complejo.
Por lo tanto, nuestra primera misión es conocer elementos tales como:
- ¿Cuántas LOC (líneas de código) tiene?
- ¿Cuántas funciones? ¿Son sencillas o complejas?
- ¿Utiliza APIs de terceros?
- ¿Está bien comentado?
- ¿Existe documentación? ¿Está actualizada?
No podemos olvidarnos de requisitos externos que pueden complicar el proceso. Hace unos años participé en proyecto militar en el que recibí un código fuente con las siguientes características:
- El código fuente era de la versión 7.
- La documentación era de la versión 4 (a partir de ahí desarrollaron con prisa y no hubo tiempo para actualizar… ¿os suena?).
- Para compilar era necesaria una llave USB… que no tenía y que tardó varios meses en llegar.
Desde luego no es el mejor escenario. Cuando te enfrentas a un proyecto así, cuanta más información puedas obtener, más sencillo será tu trabajo.
Mi consejo cuando te enfrentes a un proceso de auditoría de código es: insiste, profundiza y no tengas miedo a ser pesado. Puede que preguntando tres veces en lugar de una obtengas datos que te sean de mucha ayuda.
Herramientas de información
En nuestro acercamiento al código fuente, nos será de mucha ayuda tener una visión de conjunto antes de entrar a saco con el código. Por suerte dispones de gran cantidad de herramientas que te pueden ayudar en este paso.
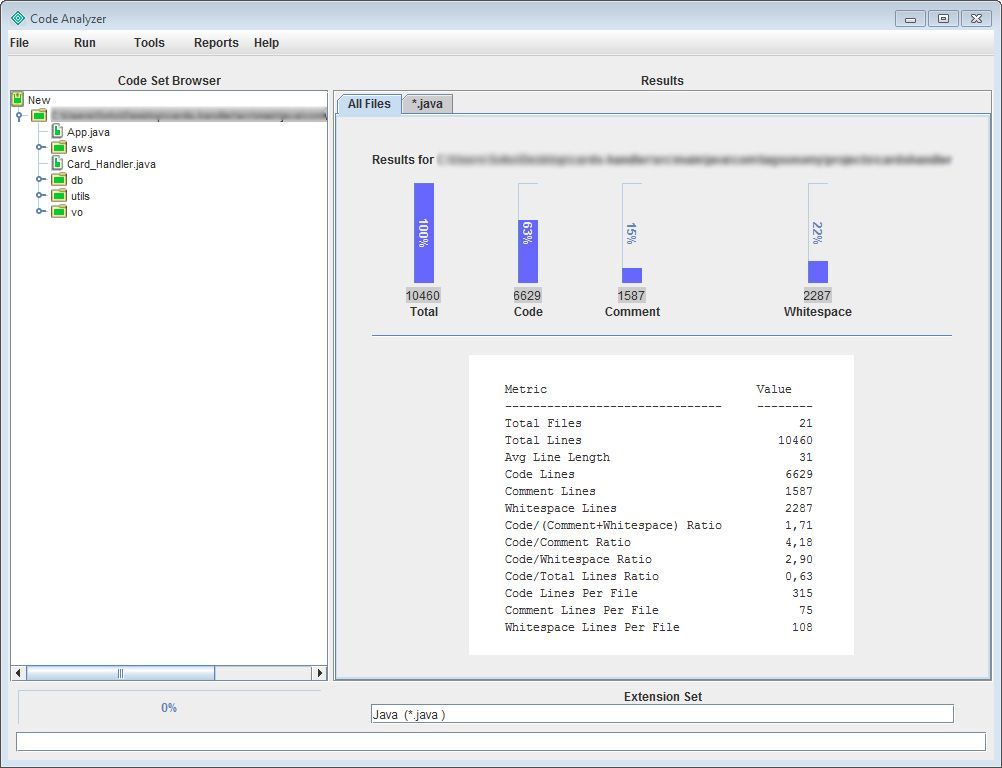
En la siguiente captura podéis ver un ejemplo de una de esas herramientas (en este caso Code Analyzer) evaluando un pequeño proyecto java.
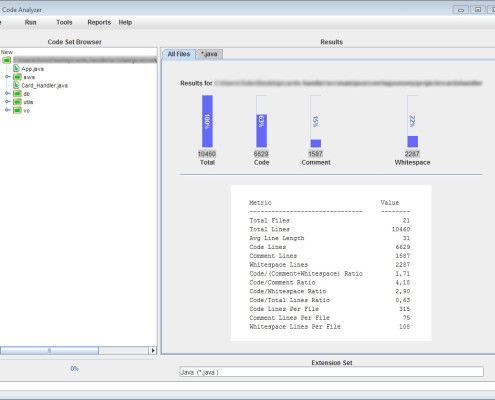
Como podéis ver, de forma rápida nos ofrece una visión de conjunto indicando LOC, comentarios, espacios en blanco…
Complejidad del código
El siguiente paso será evaluar la complejidad funcional de lo que tenemos entre manos. Esto será una tarea sencilla si recibimos una buena documentación en la que todos los procesos estén descritos a nivel funcional (si hay diagramas de secuencia entonces será todo un éxito).
Si no lo tenemos, tendremos que evaluar el código realizando una tarea inicial de análisis de caminos independientes que se pueden tomar en los if-else, switches, cases, bucles… para trazar un mapa y poder contarlos.
¡Ojo! No te confundas, no se trata de contar sin más, debes evaluar las opciones. Mejor vemos un ejemplo, ¿no?
if (var > 10){
if (var > 20){
print "Mayor que 20";
}
else{
print "Entre 10 y 20";
}
}
else{
print "Menor que 10";
}
En este caso podemos ver claramente que la existencia de dos condicionales hace que existan tres caminos diferentes de ejecución:
- Camino A: La variable es menor que 10.
- Camino B: La variable se encuentra entre 10 y 20.
- Camino C: La variable es mayor que 20.
Esto se puede hacer a mano, pero también dispones de herramientas que te ayudarán a hacerlo de forma más sencilla, aquí tienes algunas de ellas:
En esta captura puedes ver el resultado de consultar la complejidad utilizando el plugin Metrics para Eclipse sobre el proyecto JAVA anterior:
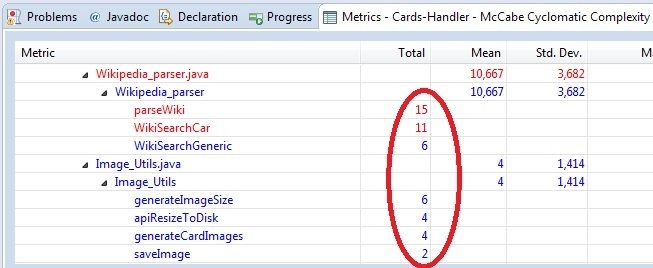
El resultado lo podremos interpretar de la siguiente forma:
|
Medidad de complejidad
|
Significado
|
|
1-10
|
- Código estructurado con facilidad para hacer pruebas.
- Poco riesgo de seguridad asociado.
- Coste de auditoría bajo.
|
|
10-20
|
- Código complejo con dificultad media para pruebas.
- Riesgo medio de seguridad.
- Coste de auditoría medio.
|
|
20-40
|
- Código muy complejo con gran dificultad para pruebas.
- Riesgo alto de seguridad.
- Coste de auditoría elevado.
|
|
>40
|
- Código excesivamente complejo, es muy probable que no se puedan realizar todas las pruebas.
- Riesgo muy alto de seguridad.
- Coste de auditoría muy elevado.
|
NOTA: Si quieres profundizar más sobre el cálculo de la complejidad ciclomática, estos enlaces te serán de gran utilidad:
Planificando la auditoría
Una vez tenemos el código y hemos comprendido a qué nos enfrentamos (LOC, complejidad, documentación…) estamos en condiciones de afrontar el proceso y qué mejor forma que haciendo eso que tanto nos gusta, planificar.
Lo principal será definir el equipo que se va a encargar de realizar la auditoría, puede ser una persona o muchas más (como siempre, dependerá del presupuesto, la urgencia y varios elementos específicos del proyecto).
La recomendación es que se trate de varias personas con formación y experiencia en ámbitos diferentes. Sería ideal contar con alguien especializado en diferentes entornos de desarrollo (escritorio, móvil, web), lenguajes o sistemas.
Planificaremos entonces una serie de sesiones semanales en las que cada miembro del equipo tendrá plena libertad para usar aquellas herramientas o técnicas con las que se sienta más cómodo (de ahí la importancia de que el equipo tenga diferentes perfiles).
Cada día se realizará una reunión de seguimiento corta (siguiendo la idea de SCRUM) y después se iniciará el proceso por el que cada miembro se encargará de un máximo de 1000 LOC/h y durante un máximo de 3 horas, ya que la concentración es muy importante en este proceso y no conviene que el equipo esté cansado o aburrido (lo cual es fácil cuando llevas un par de horas leyendo código de otro…).
¿Qué nos queda?
Tenemos y conocemos el código, longitud, complejidad, documentación y requisitos de funcionamiento. Tenemos al equipo listo con una cantidad de horas y LOC asignadas. ¿Tenemos ganas de empezar?
Pues nos vemos en la siguiente entrada en la que profundizaremos en las fases de la auditoría, en las tareas habituales y en un montón de cosas más.
Como siempre digo, si ves algún error, no estás de acuerdo con lo que cuento o quieres hacer alguna aportación, no dudes en pasarte por los comentarios.