
Contenedores Linux y seguridad. Docker
Un poco de historia
Las técnicas de para circunscribir un proceso a un espacio aislado dentro de un sistema operativo no es algo nuevo. El primer antecedente, chroot, se remonta a 1979 y fue introducido como un concepto en desarrollo para sistemas Unix que permitía aislar dentro una ruta un proceso y sus hijos de modo que para ellos, esa ruta pareciese ser el directorio raíz. Más adelante, en 1982, chroot se incorpora a sistemas operativos BSD. En 1991 es utilizado por William Cheswick, un programador e investigador en seguridad de red, para implementar una honeypot y monitorizar comportamientos maliciosos.
Estas semillas iniciales supusieron los primeros pasos de lo que se acabaría consolidando como virtualización de sistemas con la aparición de hypervisores, software que permite la ejecución virtual de sistemas completos emulando tanto el hardware como el sistema operativo.
Dejando a un lado lo que a virtualización de hardware e hypervisores se refiere, en este artículo vamos a ofrecer una visión de los contenedores, una tecnología que, partiendo de la idea base de chroot, extiende este concepto para conseguir ejecutar entornos aislados del sistema. Con el uso de contenedores, en realidad no se está virtualizando nada sino que se están manteniendo en un espacio aislado (namespace) los procesos y ficheros necesarios mientras se reutiliza el kernel del sistema anfitrión.
La primera aproximación sólida a los contenedores en sistemas *nix aparece en FreeBSD en el año 2000 con la introducción del comando jail que orienta y amplia las funcionalidades de chroot. A partir de ahí, se empieza a extender a otras plataformas como Solaris, el sistema operativo de Sun Microsystems, que en 2005 incorpora Solaris Zones permitiendo crear subsistemas aislados denominados zonas. De igual forma otros fabricantes como IBM con AIX WPARs, o HP con HP-UX Containers adoptan implementan soluciones similares.
Finalmente, en 2008, llega a Linux con LXC (Linux Containers) que da soporte al kernel para los namespaces. Los namespaces constituyen el elemento base de los contendores y es una funcionalidad del kernel que proporcionan facilidades para crear una abstracción del sistema de modo que, todo lo que sucede fuera del espacio del contenedor sea invisible al interior.
¿Virtualización? ¿Qué virtualización?
La evolución de los namespaces ha permitido pasar del “enjaulamiento” de rutas de chroot hasta los contenedores que proporcionan espacios aislados en todos los niveles: espacio de usuario, espacio de procesos, de red, puntos de montaje, etc. Esta situación se acerca a estado parecido a la virtualización que quizás podemos entender mejor como una virtualización de sistema operativo o mejor dicho, una “paralelización” puesto que se comparte una arquitectura y un kernel y no se virtualiza ningún elemento hardware o dispositivo lo que contribuye a un mejor rendimiento.
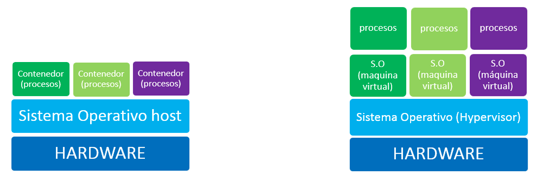
Contenedores vs virtualización
La popularidad y la utilización de los namespaces ha crecido enormemente desde su integración directa, en 2013 en el kernel 3.8 de Linux. Desde entonces se han consolidado y afianzado desarrollos basados en contenedores como por ejemplo Docker o CoreOS Rkt entre otros.
Contenedores vs hipervisores
Los contenedores frente a la virtualización de hardware mejoran aspectos como:
Velocidad: Compartir el kernel significa cero latencia para levantar con contenedor.
Gestión de disco: El almacenamiento basado en sistemas de ficheros con características Copy on Write (CoW) permiten reutilizar y compartir segmentos de sólo lectura de datos (imágenes base) entre distintos contenedores y trabajar con deltas (capas de escritura) que cada contenedor puede ir añadiendo y manteniendo de forma independiente. Sistemas de ficheros como Union Filesystems (aufs), OverlayFS o Brtfs permiten este modo de operación.
lobo@SI_$ docker info Containers: 3 Running: 2 Paused: 0 Stopped: 1 Images: 102 Server Version: 1.11.1 Storage Driver: aufs Root Dir: /var/lib/docker/aufs Backing Filesystem: extfs Dirs: 87 Dirperm1 Supported: true Logging Driver: json-file Cgroup Driver: cgroupfs Plugins: Volume: local Network: bridge null host Kernel Version: 4.0.0-kali1-amd64 Operating System: Kali GNU/Linux 2.0 (sana) OSType: linux Architecture: x86_64 CPUs: 1 Total Memory: 997.8 MiB
Portabilidad: Un contenedor puede trasladarse a cualquier otro sistema siempre que comparta la misma arquitectura de CPU, sin necesidad de adaptaciones. Esto permite trabajar de forma rápida y cómoda con repositorios que facilitan enormemente tareas de despliegue y desarrollo.
Por otro lado algunos inconvenientes son:
Seguridad: La implementación de los namespaces es relativamente reciente, y esto unido a que el kernel es compartido, incrementa los riesgos de comprometer el host y con ello todos los contenedores que estuviesen en el mismo. Punto único de fallo.
Entornos únicos: La imposibilidad de virtualizar otros sistemas operativos puede ser una desventaja en desarrollos multiplataforma.
Escalado y migración: Aunque existen soluciones de orquestación que permiten la ejecución multicontenedor distribuidos en distintas ubicaciones, la complejidad aumenta notablemente según lo hace el número de hosts. Esto unido a la imposibilidad de migración “en caliente” para mover contenedores supone una desventaja ante soluciones completas de virtualización.
Contenedores y seguridad. Namespaces, cgroups, capabilities y más.
El aislamiento en los contenedores Linux se sustenta principalmente en dos funcionalidades del kernel: los namespaces y cgroups, que haciendo una aproximación sencilla podemos identificar como los mecanismos que proporcionarán la base para el aislamiento a nivel cualitativo y cuantitativo respectivamente. Desde la versión de kernel 2.6, ambas tecnologías se han ido asentando paulatinamente hasta una completa integración en el kernel 3.8. Revisando la configuración del kernel (generalmente existe un fichero de config en /boot) podemos averiguar el grado de soporte en la compilación en uso, como muestran las siguientes imágenes para un kernel 4.0:
lobo@SI_$ grep -E 'NAMESPACES|_NS=y' /boot/config-4.0.0-kali1-amd64 CONFIG_NAMESPACES=y CONFIG_UTS_NS=y CONFIG_IPC_NS=y CONFIG_USER_NS=y CONFIG_PID_NS=y CONFIG_NET_NS=y CONFIG_NCPFS_NFS_NS=y CONFIG_NCPFS_OS2_NS=y
lobo@SI_$ grep CGROUP /boot/config-4.0.0-kali1-amd64 CONFIG_CGROUPS=y # CONFIG_CGROUP_DEBUG is not set CONFIG_CGROUP_FREEZER=y CONFIG_CGROUP_DEVICE=y CONFIG_CGROUP_CPUACCT=y # CONFIG_CGROUP_HUGETLB is not set CONFIG_CGROUP_PERF=y CONFIG_CGROUP_SCHED=y CONFIG_BLK_CGROUP=y # CONFIG_DEBUG_BLK_CGROUP is not set CONFIG_NETFILTER_XT_MATCH_CGROUP=m CONFIG_NET_CLS_CGROUP=m CONFIG_CGROUP_NET_PRIO=y CONFIG_CGROUP_NET_CLASSID=y
Desde el punto de vista de la seguridad, los namespaces permitirán espacios aislados para los procesos que contienen, lo que protege el sistema de acciones que suceden en el interior de la sandbox creada. Por otra parte los control groups (cgroups), permiten gestionar los recursos que se atribuyen a ciertos procesos, siendo posible de este modo asignar límites cuantitativos de CPU, memoria, acceso a disco, etc. Esto es muy útil para asegurar que el sistema no pueda ver comprometidos sus recursos.
Por otra parte, el uso de las capabilities del kernel complementaría la seguridad de los namespaces y los cgroups, restringiendo y evitando acciones privilegiadas dentro del contenedor que podrían establecer una vía de escape de la sandbox.
Todo lo anterior unido a la integración de los contenedores con mecanismos de control de acceso como SELinux completa un entorno de seguridad suficientemente robusto que, como siempre, necesita de un ajuste y una configuración apropiada.

Aislamiento en contenedores
Una vez introducidos los mecanismos principales de seguridad de los contenedores: namespaces, cgroups, capabilities y SELinux, vamos a echar un vistazo a su funcionamiento.
Namespaces
Existen 6 tipos básicos de namespaces relacionados con distintos aspectos del sistema:
- NETWORK namespace. Aislamiento de red. Así, cada namespace de red tendrá sus propios interfaces de red, direcciones de red, tablas de enrutamiento, puertos de red, etc.
- PID namespace. Aísla el espacio de identificadores de proceso. Un contenedor tendrá su propia jerarquía de procesos y su proceso padre o init (PID 1).
- UTS namespace. Aísla el dominio y hostname, permitiendo a un contenedor poseer su propio dominio de nombres.
- MOUNT namespace. Aísla los puntos de montaje de los sistemas de ficheros que puede ver un grupo de procesos. Este namespace fue el punto de partida que nació con chroot.
- USER namespace. Aísla identificadores de usuarios y grupos. Así dentro un contenedor es posible tener un usuario con ID 0 (root) que se corresponda con un ID de usuario cualquiera en el host.
- IPC namespace. Aísla la intercomunicación entre procesos dentro del espacio.
Así, sobre un kernel con soporte para namespaces es posible aislar procesos utilizando las llamadas al kernel (clone) con los flags necesarios (CLONE_NEWNET, CLONE_NEWPID, CLONE_NEWUTS, CLONE_NEWNS, CLONE_NEWUSER, CLONE_NEWIPC) según lo deseado. Esta es la base utilizada por frameworks como Docker para crear contenedores.
Utilizando Docker, verifiquemos en un ejemplo como los procesos dentro de un contenedor tienen namespaces distintos, lo que significa que se mueven en espacios independientes y aislados entre sí. En el escenario mostrado en la imagen siguiente, podemos ver la ejecución de una shell (sh) dentro un contenedor utilizando Docker. Con el comando “docker ps” mostramos efectivamente, un contenedor con nombre loving_albatanni que está ejecutando una shell. El pid del contenedor es 11344 desde el punto del host que, correspondería al proceso 1 dentro del mismo y que identifica al proceso “sh”, el primer comando ejecutado en el contenedor.
Podemos verificar los cambios de namespaces con el comando pstree con el flag –S, que nos mostrará la jerarquía de procesos, indicándonos entre paréntesis los cambios de contexto en los namespaces. De forma más directa, inspeccionando /proc identificamos claramente identificadores distintos en los namespaces de proceso 1 del host y el proceso 11344 del contenedor (pid 1 dentro).
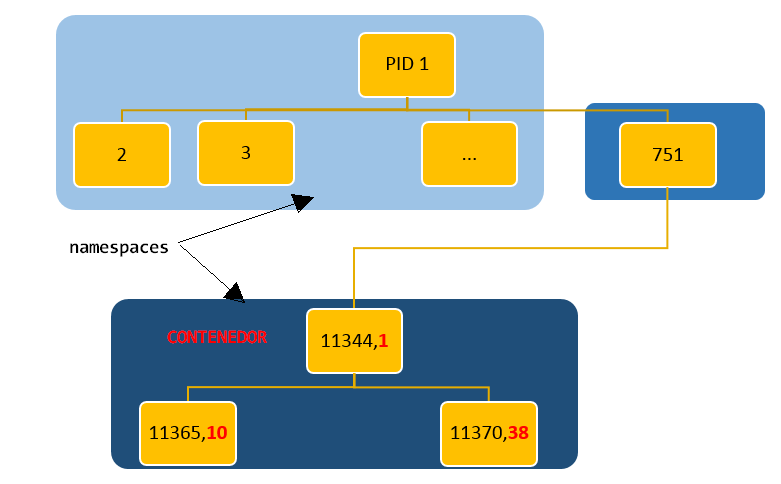
Namespace de procesos
lobo@SI_$ docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES c1c14004ad6d debian "bash" 6 days ago Up 6 days nostalgic_leavitt lobo@SI_$ docker inspect loving_albatanni | grep -i pid "Pid": 11344, "PidMode": "", "PidsLimit": 0, lobo@SI_$ pstree -gsS 11344 systemd(1)───docker(751,mnt)───docker-containe(828)───docker-containe(13340)───bash(11344,ipc,mnt,net,pid,uts)───s lobo@SI_$ ls -l /proc/1/ns total 0 lrwxrwxrwx 1 root root 0 jun 8 11:22 ipc -> ipc:[4026531839] lrwxrwxrwx 1 root root 0 jun 8 11:22 mnt -> mnt:[4026531840] lrwxrwxrwx 1 root root 0 jun 8 11:22 net -> net:[4026531957] lrwxrwxrwx 1 root root 0 jun 8 11:22 pid -> pid:[4026531836] lrwxrwxrwx 1 root root 0 jun 8 11:22 user -> user:[4026531837] lrwxrwxrwx 1 root root 0 jun 8 11:22 uts -> uts:[4026531838] lobo@SI_$ lobo@SI_$ ls -l /proc/11344/ns total 0 lrwxrwxrwx 1 root root 0 jun 6 08:34 ipc -> ipc:[4026532153] lrwxrwxrwx 1 root root 0 jun 6 08:34 mnt -> mnt:[4026532151] lrwxrwxrwx 1 root root 0 jun 6 08:34 net -> net:[4026532156] lrwxrwxrwx 1 root root 0 jun 6 08:34 pid -> pid:[4026532154] lrwxrwxrwx 1 root root 0 jun 8 11:22 user -> user:[4026531837] lrwxrwxrwx 1 root root 0 jun 6 08:34 uts -> uts:[4026532152] lobo@SI_$ lobo@SI_$ docker attach loving_albatanni root@c1c14004ad6d:/# ps aux USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND root 1 0.0 0.1 20244 1960 ? Ss Jun01 0:00 bash root 17 0.0 0.1 17500 1828 ? R+ 09:26 0:00 ps aux
NOTA: Nótese que no hay cambio en el namespace de usuario ya que este es opcional y debe fijarse al arrancar docker. Al no haber cambio en el namespace de usuario, el usuario dentro del contenedor es el mismo usuario fuera de él. Esto quiere decir que root dentro del contenedor es root fuera, lo que entraña un riesgo de seguridad que conviene evitar configurando oportunamente la ejecución.
Cgroups
Los grupos de control o cgroups son una excelente herramienta para controlar la asignación de recursos hardware. Para ello se definen jerarquías en árbol en las que se agrupan los procesos del sistema apoyándose en una ruta del sistema de ficheros, generalmente ubicado en /sys/fs/cgroup (debian) o /cgroup (redhat). Simplificando, podemos imaginar como el tradicional ulimit pero mucho más extenso y granular. No es objeto de este artículo profundizar en la descripción funcional de los grupos de control, pero si es interesante ver como gracias a ello es posible recortar recursos a un contenedor y por tanto contribuir a aislar su impacto en el sistema.
De nuevo utilizando docker arrancamos dos contenedores uno sin especificar límite de memoria y un segundo aplicando un límite de 64mb utilizando el flag –m 64mb. Para demostrar la restricción de memoria corremos el programa stress para consumir 100Mb de memoria ( stress –vm 1 –vm-bytes 100M )
lobo@SI_$ docker run -it -m 64mb debian bash WARNING: Your kernel does not support swap limit capabilities, memory limited without swap. root@39769040071c:/# stress --vm 1 --vm-bytes 100M stress: info: [6] dispatching hogs: 0 cpu, 0 io, 1 vm, 0 hdd lobo@SI_$ docker run -it debian bash WARNING: Your kernel does not support swap limit capabilities, memory limited without swap. root@21e5fd19b14963:/# stress --vm 1 --vm-bytes 100M stress: info: [6] dispatching hogs: 0 cpu, 0 io, 1 vm, 0 hdd
Con el comando systemd-cgtop podemos ver el consumo de recursos por distintos grupos de control y verificamos efectivamente que, uno de los contenedores no es capaz de consumir más de 64Mb:
lobo@SI_$ systemd-cgtop

Las propiedades del contenedor y sus límites podemos comprobarlas con docker inspect:
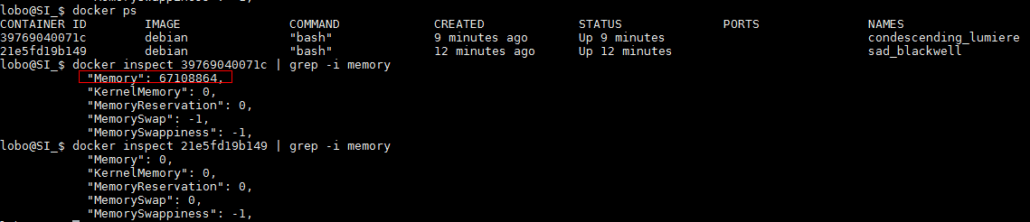
Capabilities
Las capabilities proporcionan un buen mecanismo para restringir privilegios. En el caso de los contenedores es especialmente útil y por ejemplo en Docker, por defecto cualquier contenedor sufre un recorte de capabilities que impiden numerosas operaciones privilegiadas tales como el montaje de sistemas de ficheros o administración de interfaces de red entre otras.
Verifiquemos con un ejemplo real como se produce este recorte de capabilities comparando una shell en el host y una shell en el contenedor.
Una shell de root en el host tiene todas las capabilities:
lobo@SI_$ echo $$ 26599 lobo@SI_$ cat /proc/26599/status | grep ^Cap CapInh: 0000000000000000 CapPrm: 0000003fffffffff CapEff: 0000003fffffffff CapBnd: 0000003fffffffff lobo@SI_$ capsh --decode=0000003fffffffff 0x0000003fffffffff=cap_chown,cap_dac_override,cap_dac_read_search,cap_fowner, cap_fsetid,cap_kill,cap_setgid,cap_setuid,cap_setpcap,cap_linux_immutable, cap_net_bind_service,cap_net_broadcast,cap_net_admin,cap_net_raw,cap_ipc_lock, cap_ipc_owner,cap_sys_module,cap_sys_rawio,cap_sys_chroot,cap_sys_ptrace, cap_sys_pacct,cap_sys_admin,cap_sys_boot,cap_sys_nice,cap_sys_resource, cap_sys_time,cap_sys_tty_config,cap_mknod,cap_lease,cap_audit_write, cap_audit_control,cap_setfcap,cap_mac_override,cap_mac_admin,cap_syslog, cap_wake_alarm,cap_block_suspend,37 lobo@SI_$
Sin embargo, por defecto en un contenedor se restringen capabilities y como se puede ver en la siguiente imagen de un contenedor docker se eliminan todas menos unas pocas:
lobo@SI_$ docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 39769040071c debian "bash" 15 minutes ago Up 15 minutes condescending_lumiere 21e5fd19b149 debian "bash" 17 minutes ago Up 17 minutes sad_blackwell lobo@SI_$ docker inspect condescending_lumiere | grep -i pid "Pid": 26579, "PidMode": "", "PidsLimit": 0, lobo@SI_$ cat /proc/26579/status | grep ^Cap CapInh: 00000000a80425fb CapPrm: 00000000a80425fb CapEff: 00000000a80425fb CapBnd: 00000000a80425fb lobo@SI_$ capsh --decode=00000000a80425fb 0x00000000a80425fb=cap_chown,cap_dac_override,cap_fowner,cap_fsetid,cap_kill, cap_setgid,cap_setuid,cap_setpcap,cap_net_bind_service,cap_net_raw, cap_sys_chroot,cap_mknod,cap_audit_write,cap_setfcap
Esto se traduce en restricciones dentro del contenedor. Para ilustrar con un ejemplo: obsérvese que se han quitado las capabilities cap_net_admin y cap_sys_time, de modo quelo el kernel denegaría operaciones de cambio de fecha del sistema o manipulación de interfaces de red dentro del contenedor (aun siendo root):
lobo@SI_$ docker exec -it condescending_lumiere bash root@39769040071c:/# root@39769040071c:/# date Wed Jun 8 10:20:25 UTC 2016 root@39769040071c:/# date +Y%m%d -s "20160609" date: cannot set date: Operation not permitted root@39769040071c:/# ifconfig eth0 eth0 Link encap:Ethernet HWaddr 02:42:ac:11:00:03 inet addr:172.17.0.3 Bcast:0.0.0.0 Mask:255.255.0.0 inet6 addr: fe80::42:acff:fe11:3/64 Scope:Link UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1 RX packets:65 errors:0 dropped:0 overruns:0 frame:0 TX packets:43 errors:0 dropped:0 overruns:0 carrier:0 collisions:0 txqueuelen:0 RX bytes:234083 (228.5 KiB) TX bytes:3295 (3.2 KiB) root@39769040071c:/# ifconfig eth0:1 172.17.0.5 SIOCSIFADDR: Operation not permitted SIOCSIFFLAGS: Operation not permitted root@39769040071c:/#
Las capabilities necesarias pueden otorgarse o denegarse al arrancar el contenedor según se necesite.
Así por ejemplo podemos comprobar el efecto de quitar la capability NET_RAW necesaria para ejecutar ping:
lobo@SI_$ docker run -it --cap-drop net_raw alpine sh / # ping localhost PING localhost (127.0.0.1): 56 data bytes ping: permission denied (are you root?) / # id uid=0(root) gid=0(root) groups=0(root),1(bin),2(daemon),3(sys),4(adm),6(disk),10(wheel),11(floppy),20(dialout),26(t ape),27(video)
Comprobamos que en las capabilities del contenedor ya no tenemos CAP_NET_RAW:
lobo@SI_$ docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES a57f71180937 alpine "sh" 24 seconds ago Up 22 seconds focused_stallman lobo@SI_$ docker inspect focused_stallman | grep -i pid "Pid": 27070, "PidMode": "", "PidsLimit": 0, lobo@SI_$ cat /proc/27070/status | grep ^Cap CapInh: 00000000a80405fb CapPrm: 00000000a80405fb CapEff: 00000000a80405fb CapBnd: 00000000a80405fb lobo@SI_$ capsh --decode=00000000a80405fb 0x00000000a80405fb=cap_chown,cap_dac_override,cap_fowner,cap_fsetid, cap_kill,cap_setgid,cap_setuid,cap_setpcap,cap_net_bind_service, cap_sys_chroot,cap_mknod,cap_audit_write,cap_setfcap
El comando ping necesita de la capability NET_RAW como podemos comprobar con el comando getcap: lobo@SI_$ getcap /bin/ping /bin/ping = cap_net_raw+ep
Contenedores y aseguramiento del contenido
Los contenedores de Linux y las tecnologías subyacentes tienen un desarrollo suficientemente sólido que han propiciado que su utilización se vaya asentando y teniendo en cuenta cada vez más. No obstante, ha de tenerse en cuenta que la falta de rodaje que conlleva esta relativa inmadurez se hace extensiva a la seguridad se echa en falta aún una base de metodologías para configurar, fortalecer y verificar aspectos que sin la debida atención pueden poner en entredicho la seguridad de sistemas “containerizados”.