Amenaza Silenciosa III – Hooking (Teoría)
Amenaza Silenciosa I
Amenaza Silenciosa II – Inyección de DLL
Amenaza Silenciosa III – Hooking (Teoría)
…
Previously on Amenaza silenciosa… vimos como inyectar una DLL en un proceso. Esto sólo era el primer paso. En el post de hoy veremos cómo hookear una función.
Antes de seguir, recordemos los pasos necesarios para imitar el mecanismo de persistencia de Dridex y para qué necesitamos hookear una función:
- Ejecución de una DLL.
- Borrado de la DLL y del valor en la clave del registro (si existe).
- Inyección de la DLL en el proceso objetivo.
- Hook de la función que se encarga de terminar el proceso.
- Cuando se cierra el proceso, guardarse en disco y persistir en una clave de registro.
Marcados en negrita están la partes que ya vimos en el post anterior, hoy nos centraremos en como hookear la función que se encarga de terminar el proceso.
La idea detrás de esto es modificar el comportamiento de la función que se encarga de terminar un proceso y hacer que antes de terminar el proceso guarde nuestra DLL en el disco y escriba una clave en el registro para que se ejecute cuando el sistema se reinicie. Una vez hecho esto, ya puede proceder a cerrar el proceso.
¿Qué es el hooking?
El hooking es una técnica de intercepción de llamadas a funciones muy extendida en el mundo de la informática. En realidad, el hooking vale para modificar el comportamiento de una función, esto, como todo en la vida, se puede usar con fines más o menos legítimos. Algunos ejemplos de los posibles usos son: instrumentación de binarios, ingeniería inversa, protección de sistemas, ocultación de procesos (rootkit), etc.
Veamos como funciona:
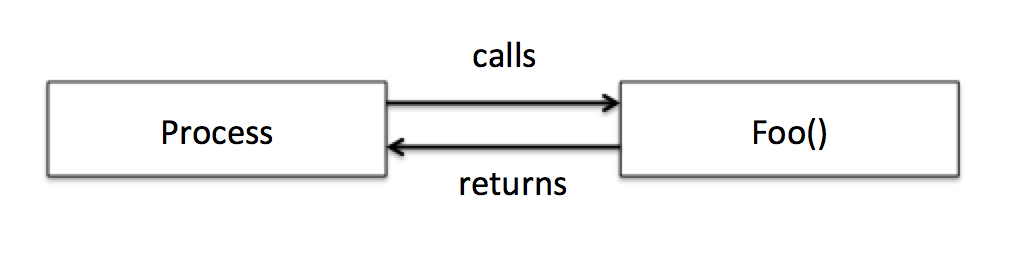
Pre-hook
Cuando un proceso llama a una función, lo normal es que se pase el flujo de ejecución directamente a esta función y, cuando esta función se termine de ejecutar, la función devolverá el flujo de la ejecución justo después de donde se realizó llamada.
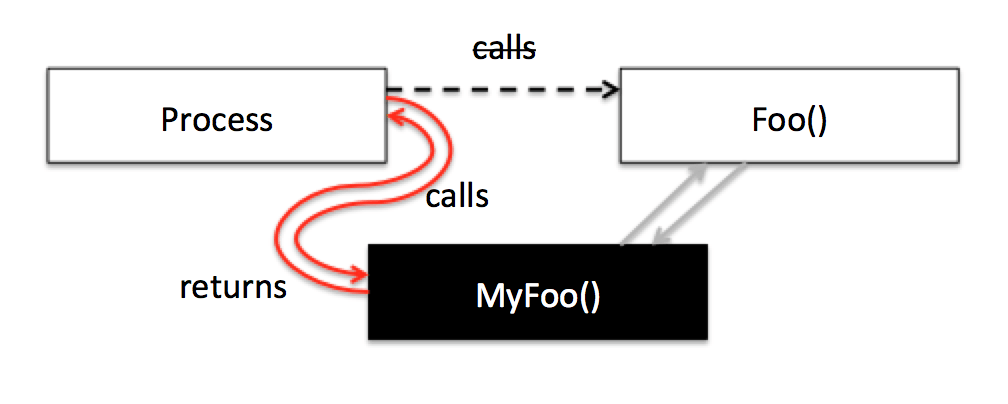
Post-hook
Cuando se hookea esta función, lo que estamos haciendo es redirigir la llamada de esa función a nuestra propia función, de esta forma podemos, modificar ligeramente el comportamiento de esa función o incluso hacer que haga cosas completamente distintas.
A continuación os dejo un pequeño video para que veáis un ejemplo de las cosas que se podrían hacer con técnicas de hooking.
Técnicas de hooking en Windows
Hay tres maneras de hookear una función en Windows:
- Usando la función SetWindowHook.
- In-line hooking.
- IAT hooking
SetWindowHookEx
La manera más simple para mi de hookear es utilizando la función que provee la API de Windows SetWindowHookEx. Esta función permite la monitorización de distintos eventos del sistema y permite muy fácilmente poner un hook en todos los procesos del escritorio.
Si estáis analizando un fichero sospechoso y veis esta función en la Import Table, es muy posible que se trate de un keylogger, unos de los usos más extendidos del uso de esta técnica de hooking en malware.
In line hooking
Esta técnica modifica el código de la función hookeada introduciendo un jmp al principio de la función. Es decir cuando el programa llama a la función, esta se ejecuta y, antes de procesar nada, salta a donde tengamos nuestra función modificada y prosigue su ejecución en nuestra función.

Pre-hook
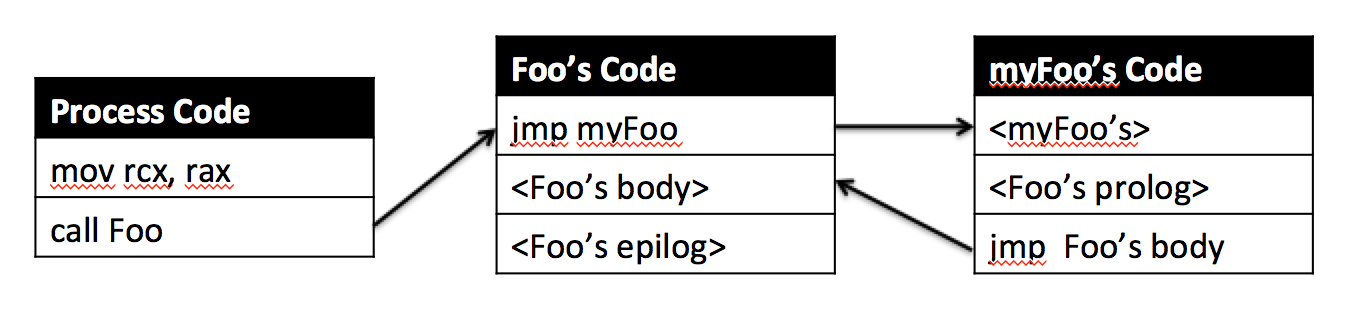
Post-hook
IAT hooking
IAT hooking es una técnica similar a la anterior, pero en lugar de sobrescribir el código de la función, lo que se hace es modificar la dirección de la función en la Import Address Table (IAT) del proceso. A continuación continuaremos con una explicación más en profundidad de esta técnica, ya que es la que he elegido para usar en la DLL.
¿Qué es la IAT?
Los ficheros ejecutables de Windows, o PE (Portable Executable), tienen una estructura que permite al sistema operativo entender estos programas. Esta estructura contiene todo lo que se necesita para ejecutar el binario e información sobre el fichero: dirección del entry point, imágenes y otros recursos que el programa puede necesitar, fecha de compilación y muchas cosas más. Estos datos se encuentran almacenados en las cabeceras del fichero PE.
Cuando un programador incluye una DLL del sistema en su programa, normalmente esa DLL no es parte del binario pero aun así el programa utiliza las funciones de estas bibliotecas enlazadas dinámicamente.
#include
En lugar de llevar todas bibliotecas incluidas el binario, el cargador de procesos de Windows (Windows Loader), al ejecutar un PE, mapea el ejecutable en memoria y carga en el espacio de memoria del proceso todas las DLL que este utiliza, entre otras cosas.
El proceso además crea una lista de la funciones y su posición en la memoria tiempo de ejecución. Esta lista es conocida como Import Address Table (IAT).
Si se sigue el esquema en este documento, se puede encontrar la IAT donde marca la siguiente imagen:
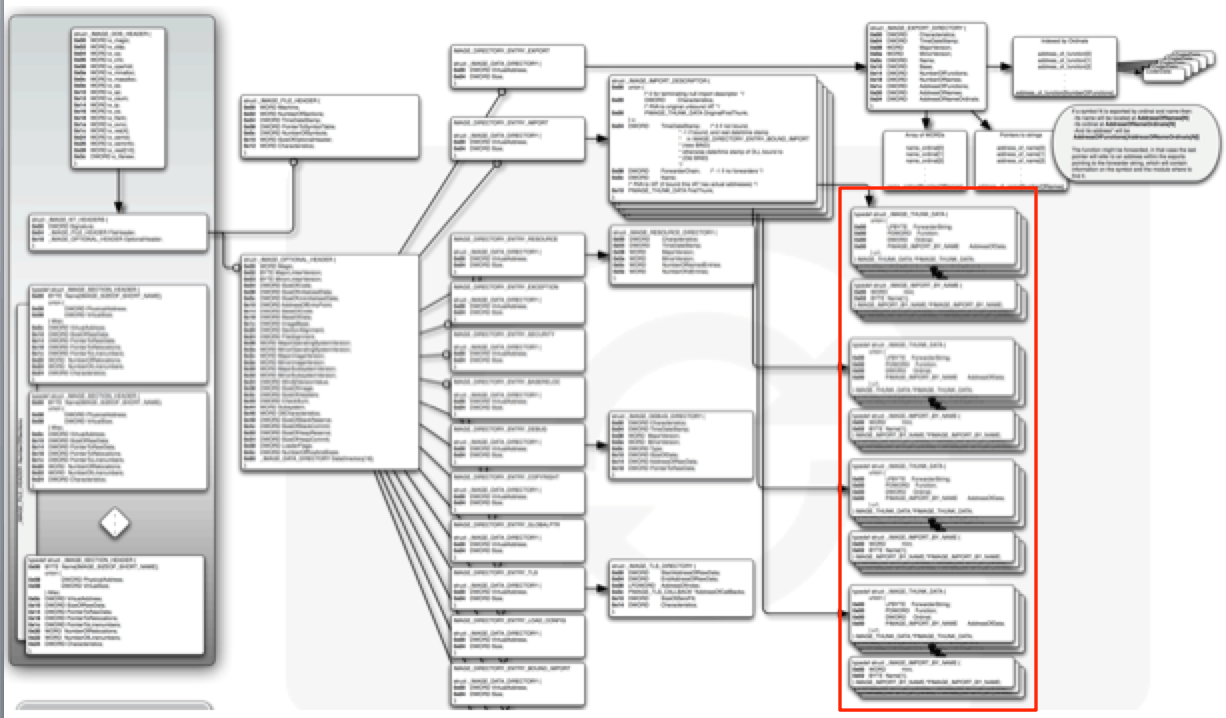
Será importante saber donde se encuentra exactamente porque en el futuro necesitaremos recorrer esta estructura en nuestra DLL para poder llegar a la IAT.
Hookeando la IAT
Cuando llamamos a una función desde cualquier lenguaje de programación, lo que pasa es que se está ejecutando la instrucción call en ensamblador. Cuando pasamos un binario por IDA, radare2 o cualquier otro desensamblador en las llamadas a funciones veremos algo parecido a esto:
.text:010031E2 lea eax, [ebp-68h] .text:010031E5 push eax .text:010031E6 call ds:GetStartupInfoA
IDA
0x1000010ca je 0x1000010d6 0x1000010cc mov rdi, rax 0x1000010cf call sym.imp.atoi
Radare2
O a esto si la función no es parte de API de Windows y el programa ha sido compilado sin símbolos:
.text:010016AF call sub_10016C6
IDA
0x100001085 call 0x100004401
Radare2
Cuando se ejecuta la función call, lo que está pasando en realidad es que el procesador salva una serie de datos que le permitirán devolver el flujo de ejecución al punto en que lo dejó, y salta a la dirección de memoria donde se encuentran las instrucciones de esta función .
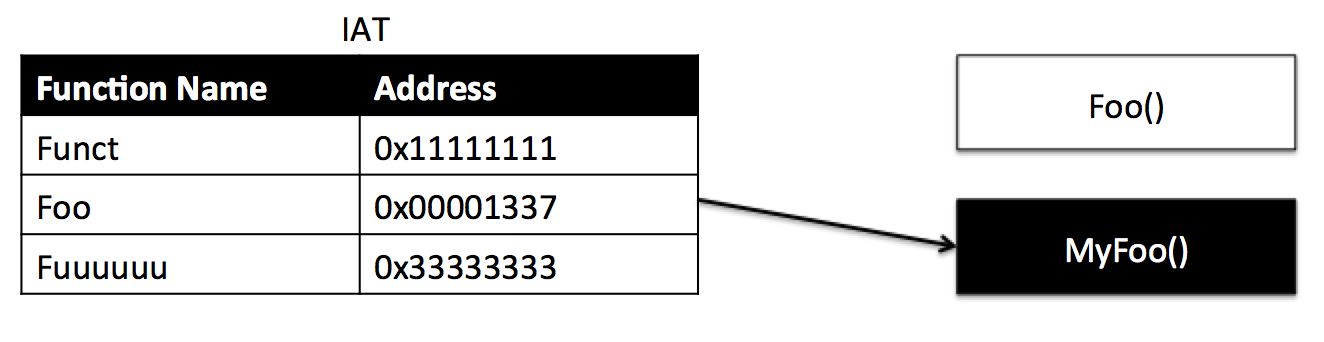
Cuando un PE invoca a una función, este va a buscar esa función a la IAT, que se ha cargado con las direcciones de las funciones en el espacio de memoria del proceso al comienzo de la ejecución, y saltará a ejecutar la función en la dirección en la que la IAT le diga que está esta función mapeada. Si somos capaces de modificar la dirección de la función que queremos hookear en la IAT y cambiarla por la de nuestra función, estaríamos tomando control sobre la ejecución de esa función. La siguiente imagen ilustra esta idea.
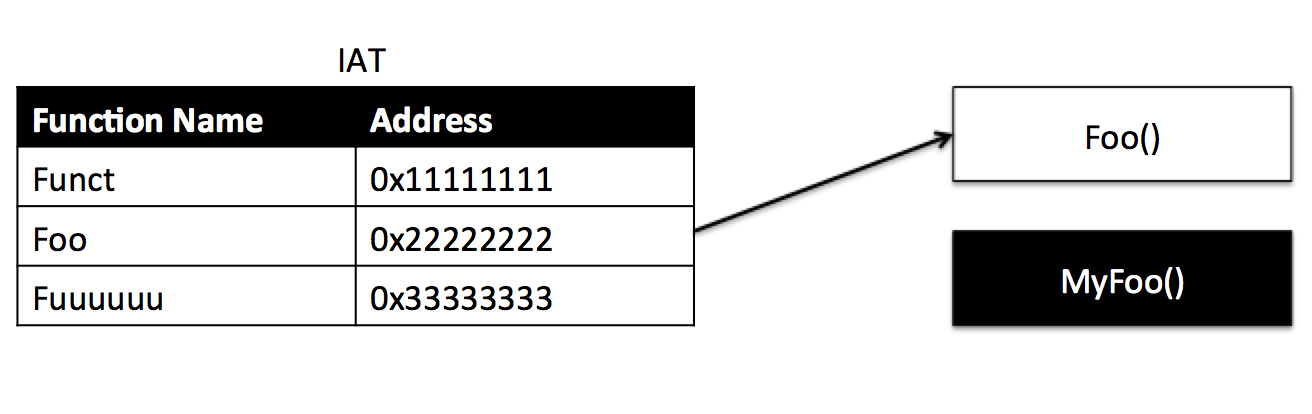
Pre-hook
Cuando el cargador de procesos de Windows ejecuta el proceso, la IAT se popula con las direcciones de las funciones y la función Foo se encuentra en la dirección de memoria 0x22222222.
Post-hook
Tras hookear la función Foo y modificar su dirección en la IAT haciendo que Foo en realidad apunte a MyFoo, podremos modificar el comportamiento de las llamadas a Foo. Si además hemos guardado la dirección de Foo en una variable, luego podremos ejecutar Foo si queremos invocando directamente su dirección de memoria, que es lo que queremos hacer con la función encargada de finalizar el proceso.
Hasta aquí la parte de teoría de este artículo, en el siguiente continuaremos con la práctica. Como siempre, aquí os dejo algunas referencias y nos vemos en la siguiente entrega de Amenaza Silenciosa.
Referencias
PE:
Esquema de la estructura de un PE [PDF]
PE Walkthrough
An In-Depth Look into the Win32 Portable Executable File Format (Matt Pietrek) [PDF]
PE @ wiki.osdev.org
Hooking
API Hooking and DLL Injection on Windows @ infosecinstitute.com
API hooking revealed @ codeproject.com
IAT Hooking
Understanding Imports @ sandsprite.com
Userland rootkits: Part 1, IAT hooks @ adlice.com
Injective Code inside Import Table @ ntcore.com
IAT Hooking explained @ guidedhacking.com
Inline hooking
Inline hooking for programmers @ malwaretech.com [part 1] [part 2]
http://www.malwaretech.com/2015/01/inline-hooking-for-programmers-part-2.html
Otros
Understanding RVAs and Import Tables @ sunshine2k.de
SetWindowsHookEx @ MSDN
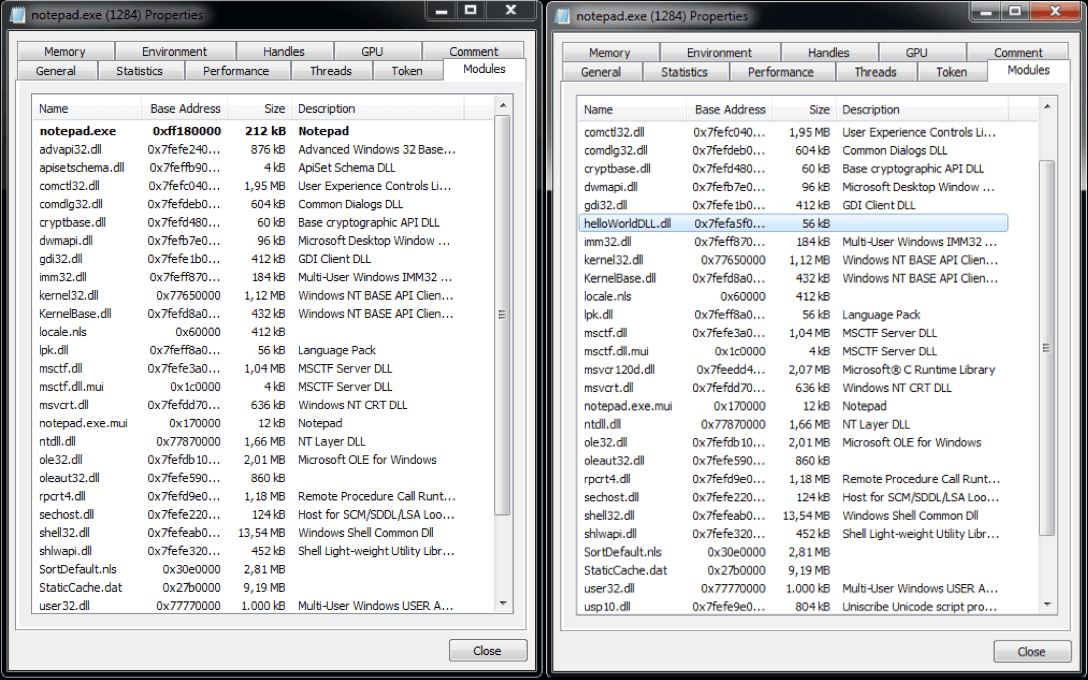
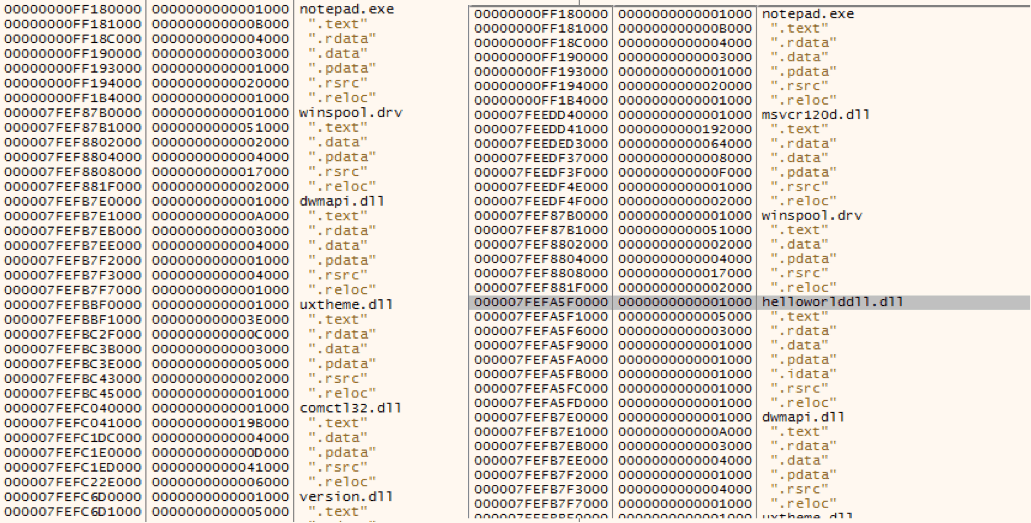
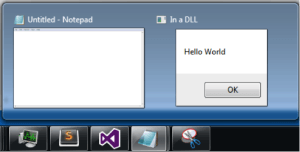
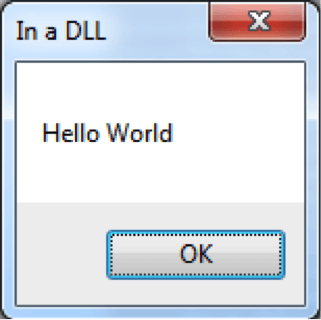 Además de estas pruebas, en el caso de helloWorldDLL.dll, se puede ver que al inyectar la HelloWorldDLL.dll salta la caja de texto definida en la función “HelloWorld”.
Además de estas pruebas, en el caso de helloWorldDLL.dll, se puede ver que al inyectar la HelloWorldDLL.dll salta la caja de texto definida en la función “HelloWorld”.