Cookies, Supercookies, y otros amigos. ¿Estoy siendo controlado?
Hace unos días volvió a salir a escena un asunto ya difundido hace casi ya un año, allá por octubre de 2014: El seguimiento que algunos proveedores de Internet y/o operadoras de telefonía móvil estaban haciendo de sus clientes. El caso se dio a conocer con Verizon y sus «perma-cookies» (http://www.wired.com/2014/10/verizons-perma-cookie/).
Aunque no hace mucho que se lleva hablando de esta forma de identificar usuarios y observarlos, todo parece indicar que no es algo novedoso.
Privacidad en Internet. Cookies
Las cookies han sido y son un método común para recoger información de los navegadores y con ello, del usuario que hay detrás. Como siempre, el principal interés es ganar dinero y se trata de obtener cuanta más información mejor, sobre los patrones de comportamiento de una persona para después explotarla convenientemente comercialmente. Lógicamente además de los intereses puramente económicos existen otros con distintos objetivos (políticos, sociales, etc).
¿Que es una cookie? Pues simplemente un «fichero» que se almacena en el navegador del ordenador o dispositivo del usuario y que servirá para obtener información e identificar al navegante al acceder a sitios web. Esto unido a la ejecución de scripts, generalmente javascript o archivos flash, se consigue procesar y recuperar muchísima información. Visítese por ejemplo en enlace de una editorial (elmundo.es) para consultar su política de cookies y enterarse de quienes y con qué objetivo hacen uso de ellas.

– Las cookies, un elemento común para gestión de información en navegadores web –
Este abuso de la privacidad del internauta ha llevado a la aparición de «leyes reguladoras» para tratar acotar el uso de las cookies o al menos, pretenderlo. Aquí en España la Agencia Española de Protección de Datos publicó la Guía sobre Cookies para ofrecer orientaciones sobre cómo cumplir con las obligaciones previstas en el apartado segundo del artículo 22 de la Ley 34/2002, de servicios de la sociedad de la información y de comercio electrónico (LSSI). Esta normativa sobre cookies se inició en 2012 y ha pasado por varias revisiones y adaptaciones, la última en 2014.
¿Supercookies? Cookies on steroids
Con las cookies tradicionales, el usuario tiene cierto control sobre su uso ya que, en cualquier momento puede decidir limpiarlas de su navegador y eliminar los rastros tanto de cookies como de archivos cacheados. No obstante la aparición de nuevas tecnologías como HSTS han sido aprovechadas para hacer más persistente el almacenamiento de información de modo que la limpieza de caché y cookies no basten para eliminar los rastros identificadores. Esto se ha pasado a denominar «supercookies» (vaya manía de poner nombre a todo) y como decimos, utilizando HSTS y los flags asociados como max-age (véase artículo sobre HSTS) se consigue, en ocasiones, el ansiado objetivo de la persistencia.
Un demostración de persistencia via HSTS podemos encontrarla aquí: http://www.radicalresearch.co.uk/lab/hstssupercookies
Éramos pocos y…. vinieron las operadoras
Recientes resultados arrojados de los estudios de la iniciativa accessnow.org para la libertad digital , han demostrado que las cookies e incluso las supercookies se quedan atrás en cuanto a lo que identificación y seguimiento de usuarios se refiere.
En el estudio realizado a través de http://amibeingtracked.com/ se demuestra como, en concreto las operadoras de telefonía móvil nos identifican y seguramente, nos observan. En este caso el método es aún más eficaz, ya que no se almacena nada en el dispositivo del cliente y por lo tanto es imposible evitar ser identificados limpiando caché o cookies. ¿Como lo hacen?. Utilizando el poder que les confiere ser nuestro proveedor de acceso a Internet.

– Operadoras móviles y privacidad –
Cabeceras HTTP
Del estudio se concluye que se están haciendo uso del protocolo http para inyectar una o más cabeceras que identifiquen al usuario al acceder a un sitio web. Para ello la operadora intercepta la solicitud http del cliente y contando con sus datos de acceso a Internet que ella misma proporciona crea unos identificadores para el usuario. Estos identificadores se usarán para crear un perfil donde la operadora irá almacenando toda la información de navegación y patrones de comportamiento del cliente. En el caso que de alguna empresa interesada solicite a la operadora información sobre clientes (seguramente tras un jugoso pago), la operadora se encargará de inyectar cabeceras http que de información del cliente que está visitando el sitio. Una vez identificado, y con la información recopilada, el sito web se encargará de dar un «tratamiento especial» al visitante.
Prueba de concepto
Tras leer el estudio The Rise of Mobile TrackingHeaders: How Telcos Around the World Are Threatening Your Privacy y visitar la página de demostración http://amibeingtracked.com/ me picó la curiosidad de saber qué cabeceras estaba inyectando mi operadora.
Para averigurarlo, escribí una página web muy simple con un pequeño script en php para recoger las cabeceras y comprobar que sucedía. Basta con acceder a la página desde tu dispositivo utilizando tu red de datos móviles:

– Inspección de cabeceras HTTP utilizando una conexión de datos móvil con Movistar –
Vaya, resulta que tenemos un par de cabeceras http ( X-Up-Subno y Tm-User-Id) que no resultan especialmente tranquilizadoras. ¿Es necesario que la operadora inserte estos identificadores del cliente en su tráfico? ¿porqué no se informa al usuario?. ¿Cual es el objetivo?
Tests de inyección
Puedes probar tu mismo el resultado con tu operadora, accediendo al test que hemos preparado. Ojo! Utiliza una conexión de datos móvil (3g, 4g, etc):
—> Test de inyección html (básico, by securityinside.info)
—> Test de inyección de accessnow.org
Uso y abuso de identificadores
Lógicamente las operadoras defenderan que su uso es legítimo y únicamente con intenciones de monitorización del servicio, pero cuando menos, resulta sospechosillo. Googleando un poco y buscando información sobre esas cabeceras llegamos al punto de partida: Verizon y sus métodos, como podemos leer en este artículo: https://www.eff.org/deeplinks/2014/11/verizon-x-uidh.
Como se sugiere en el estudio anteriormente referenciado, es muy probable que, sin consentimiento del usuario se estén almacenado perfiles y patrones de comportamiento con objeto de monetizarlo a través de su distribución para campañas de marketing o ventas personalizadas.
En este ejemplo, un supuesto cliente «Kavita» accede a la red móvil para consultar un sitio web (privacybegone.com) y su operadora manipula la petición con la inyección de cabeceras:
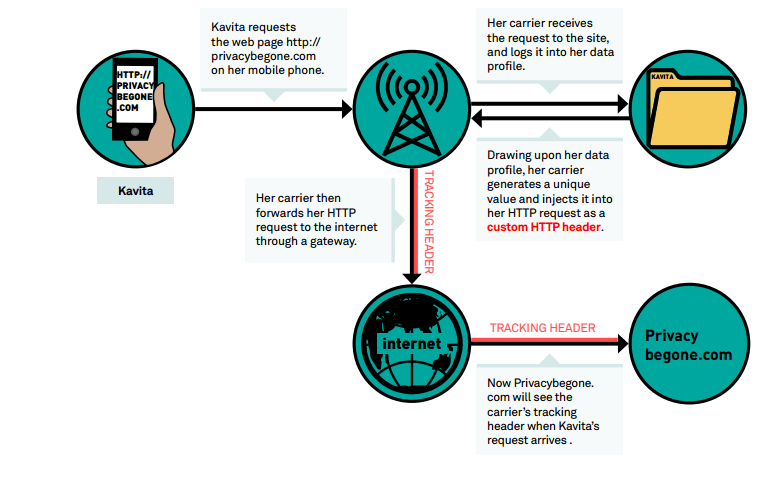
– Ejemplo de funcionamiento de inyección de cabeceras http. FUENTE: accessnow.org –
La compañía privacybegone.com, a través de las cabeceras identifica al usuario y le ofrece unos contenidos «personalizados»:
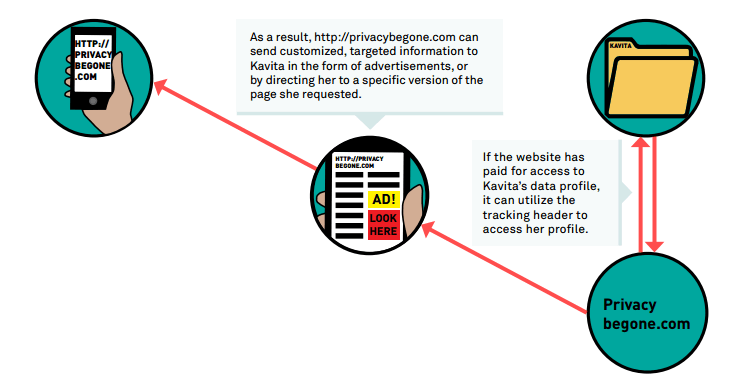
– Uso de las cabeceras para identificar al usuario . FUENTE: accessnow.org –
¿Que puedo hacer?
Pues frente a la manipulación de cabeceras por parte de tu ISP u operadora móvil, bastante poco, por no decir nada. No servirán las opciones de navegación de incógnito, ni el Do Not Track, ni limpiar cache. Es algo que sucede una vez las comunicaciones han abandonado nuestro dispositivo y donde ya no tenemos control.
La inyección de cabeceras solo funcionarán en comunicaciones http, y no será posible su inclusión en comunicaciones bajo ssl (https). Desafortunadamente aún son muy numerosos los sitios que que utilizan http.
Seguramente, esto es solo la punta del iceberg. Hoy en día la privacidad en Internet es algo más difícil de mantener.