Generalmente la forma más usual que utilizamos para reconocer el formato de un archivo es fijándonos en su extensión. En un sistema informático la aplicación empleada para abrir el fichero también se asocia (en primera instancia) con la extensión. Otro método, ampliamente utilizado en protocolos de internet como HTTP o SMTP es MIME, Multipurpose Internet Mail Extensions, que asocia un identificador tipo/subtipo para determinar la naturaleza de los datos transmitidos. Así por ejemplo, «image/jpeg» indicaría que una imagen en formato jpeg se adjunta en el mensaje. Este estándar de notación está regulado por el IANA . La fundación Apache también aporta un intesante listado con la correspondencia entre MIME y extensión de fichero.
No obstante, esta aproximación inicial para identificar un fichero de ninguna manera puede asegurarnos el contenido real del mismo. Por ejemplo, bastaría cambiar la extensión de «.pdf» por «.jpeg» en un archivo para que el sistema, en lugar de abrir el archivo con Adobe Reader, lo intentase con un visualizador de imágenes. Este comportamiento puede ser problemático desde el punto de vista de la seguridad, en el sentido que se se malinterpreta un contenido y que podría utilizarse de manera no esperada para realizar acciones maliciosas.
Cabeceras de fichero y números mágicos
Una forma más precisa para determinar el tipo de fichero es observando el contenido del mismo. Existen múltiples estándares de formato que utilizan unos pocos bytes (en binarios) o caracteres alfanuméricos (en ficheros de texto) del comienzo del archivopara identificar el contenido. Esta convención está estandarizada y se conoce como números mágicos. Un listado puede encontrarse en el siguiente enlace: https://en.wikipedia.org/wiki/List_of_file_signatures.
De este modo, una aplicación que trate de identificar de forma segura un archivo antes de abrirlo, comprobaría la cabecera del mismo para determinar el tipo de contenido. Esta estrategia que en principio podría parecer ideal, tampoco proporciona un método infalible debido a la «flexibilidad» de algunos formatos y la poca rigurosidad de ciertas aplicaciones a la hora de parsear y comprobar las cabeceras y opciones de los mismos. Este problema se pone de manifiesto cuando un mismo fichero puede ser interpretado de distintas formas, dependiendo de la aplicación que lo procese y de las opciones de formato que verifica. Este tipo de archivo se conoce con el nombre de archivo poliglota.
Archivos poliglotas: varios en uno
¿Que es un archivo poliglota?
Un archivo poliglota es un fichero con múltiples formatos válidos, es decir, que tiene una estructura que lo hace interpretable por distintas aplicaciones ya que cumple con el formato esperado por las mismas. Así por ejemplo, un mismo fichero de estas características podría ser abierto como una imagen por un visor de imágenes o ejecutar un script al abrirse con un navegador o un intérprete de comandos.
¿Por qué existen archivos poliglotas? ¿Que riesgos existen?
En general, podemos decir que se debe a una excesiva flexibilidad a la hora de definir los formatos. Por ejemplo, un archivo PDF permite posicionar su «número mágico» ( 25 50 44 46 en hexadecimal o %PDF en ascii) dentro de los primeros 1024 bytes del archivo, mientras que otros (JPG,GIF, ELF, etc) son menos flexibles y obligan un «offset 0» es decir, a posicionar el número mágico justo al principio del archivo.
El riesgo proviene del hecho de que un mismo fichero puede ser interpretado de distintas formas y, aprovechando esta circunstancia, se pueden realizar tareas no deseadas. Así, en un archivo con extensión .pdf podría incrustarse código javascript, php o shell script y ejecutarse en un cliente, en un servidor web o en un intérprete de comandos, si la organización de los datos dentro del fichero conserva una estructura válida para todos los formatos pretendidos.
Ejemplos de achivos poliglotas
Veamos un ejemplo muy sencillo (e inofensivo) donde se ha incrustado un comando linux (xeyes) en un pdf y, sin alterar su validez, comprobamos como puede abrirse con un visor de pdf y ejecutarse como un script bash:
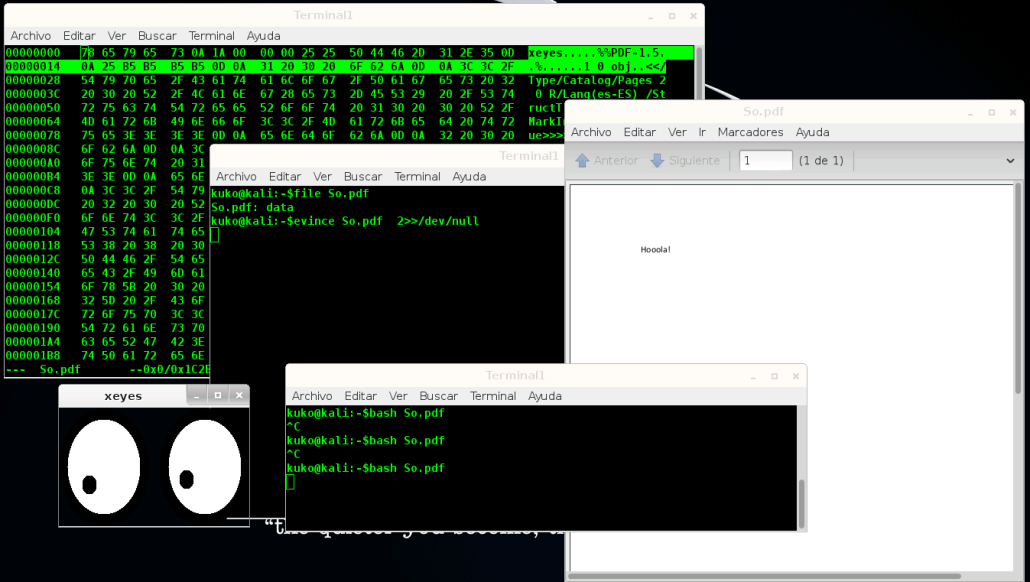
Obsérvese en el volcado hexadecimal, como en la cabecera justo al comienzo del archivo, aparece el comando xeyes. Unos pocos bytes más adelante aparece el identificador del PDF, resultando un archivo válido puesto que este formato permite un offset de hasta 1024 bytes para posicionar la cabecera (Adobe Reader).
Otro ejemplo: un archivo de imagen bmp que a la vez contiene un comando ejecutable windows (calc.exe):

Ataques poliglotas
Este tipo de archivo constituye en sí un problema de seguridad y, es responsabilidad del usuario o una aplicación establecer las comprobaciones oportunas que eviten situaciones de peligro en caso de un uso malintencionado. En esta materia Ange Albertini () es un reconocido investigador que ha publicado numerosos trabajos relacionados con los formatos de archivo con muchos ejemplos y métodos para construir archivos poliglotas. En su repositorio de Github ( https://github.com/corkami ) encontraréis gran cantidad de información para profundizar en este interesante campo.
Conclusiones:
Como el propio Ange dice: No olvides abrir tu pdf en un editor hexadecimal , cargar una imagen en un reproductor de sonido… o ejecutar un documento en intérprete de comandos. Eso sí, siempre desconfiando de las apariencias.
Bola extra
En este enlace se proporciona un pdf. Échale un vistazo… y reprodúcelo con VLC player 😉
Video: Funky File Formats (Ange Albertini)





 Honestamente, es sólo la confirmación de algo que ya sabía en algunos círculos desde hace mucho. Lo que sí que me sorprende es que esto no haya aparecido en los periódicos (nota: es posible que si que haya alguna publicación, pero como expatriado sólo miro los periódicos más grandes, y no he visto nada al respecto). Las implicaciones de esto pueden ser muy grandes y estaría bien saber bajo que marco legal se utilizan este tipo de herramientas.
Honestamente, es sólo la confirmación de algo que ya sabía en algunos círculos desde hace mucho. Lo que sí que me sorprende es que esto no haya aparecido en los periódicos (nota: es posible que si que haya alguna publicación, pero como expatriado sólo miro los periódicos más grandes, y no he visto nada al respecto). Las implicaciones de esto pueden ser muy grandes y estaría bien saber bajo que marco legal se utilizan este tipo de herramientas.